Abstract
Overview
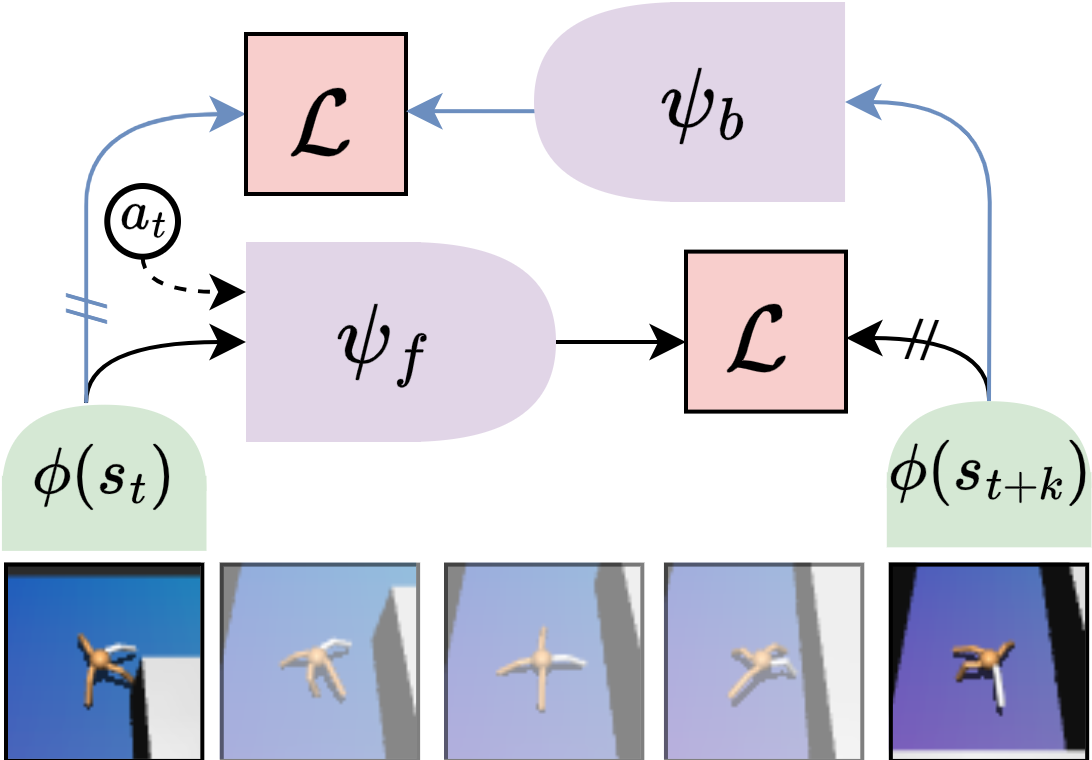
To learn better policy representations for generalization, we utilize an auxiliary self-predictive objective that predicts a future representation via . We can also predict backwards with a separate predictor . The target offset is sampled geometrically .
Representation Visualization

Representation visualizations for different auxiliary losses with BC, indicating cosine similarity between forward prediction from all states the goal's (★) representation .
OGBench Results

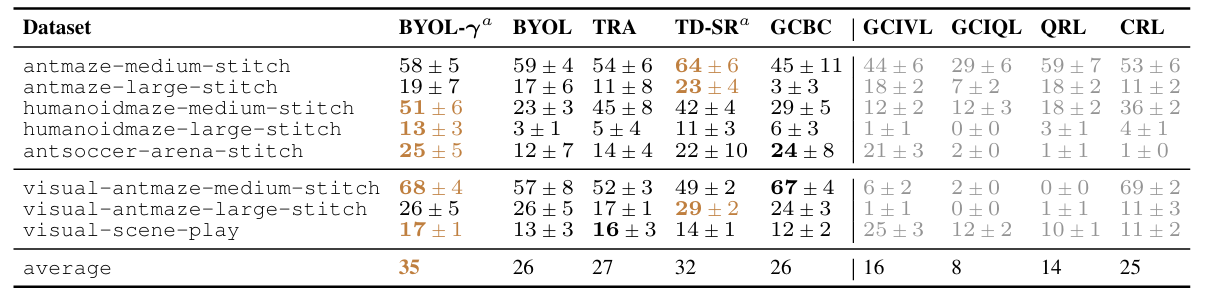
We find that on OGBench tasks requiring combinatorial generalization, using
Horizon Generalization
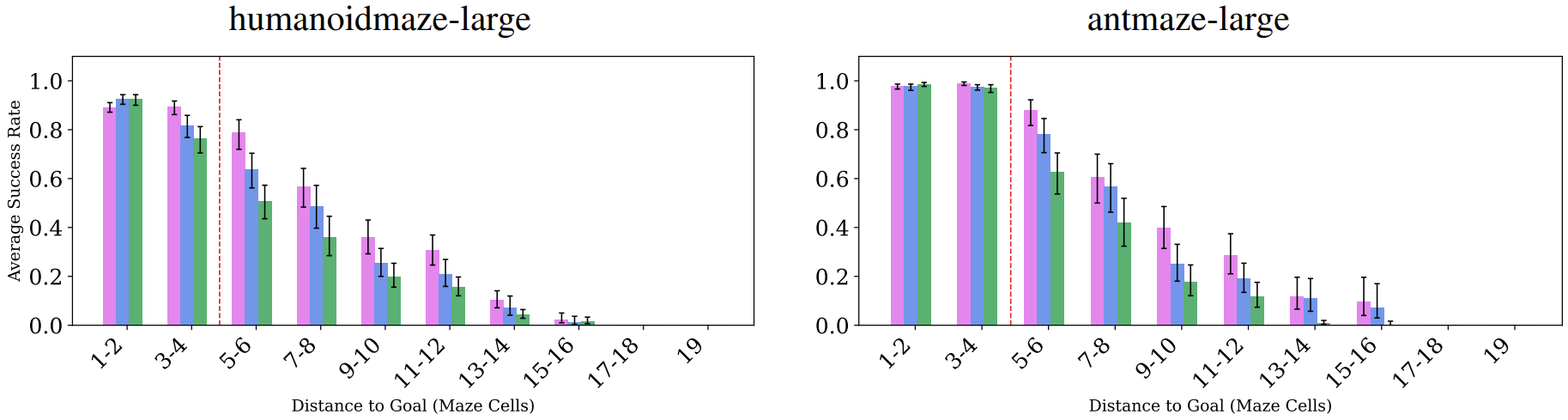

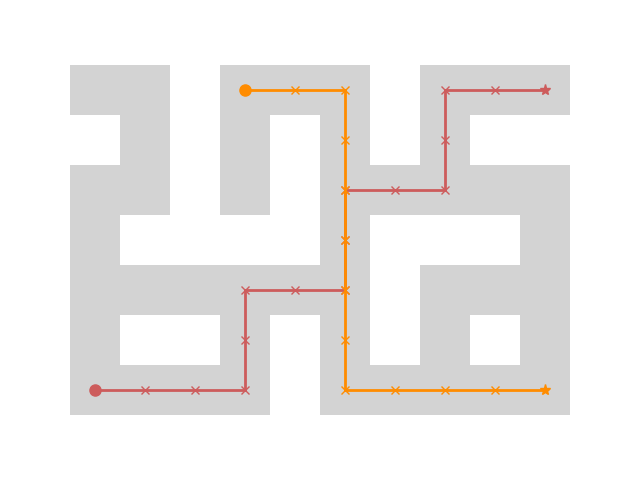
We conduct experiments to understand how success rate changes as an agent has to reach more challenging goals further away from its starting position. We consider the same base 5 evaluation tasks used in our main evaluation, but construct intermediate waypoints as shorter horizon goals along the shortest path from the start (●) to the final goal (★). We find that our objective can help generalize to further and more challenging goals.
BibTeX
@misc{lawson2025selfpredictiverepresentationscombinatorialgeneralization,
title={Self-Predictive Representations for Combinatorial Generalization in Behavioral Cloning},
author={Daniel Lawson and Adriana Hugessen and Charlotte Cloutier and Glen Berseth and Khimya Khetarpal},
year={2025},
eprint={2506.10137},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2506.10137},
}